使用 Python 抓取网页

Web 爬虫是一种强大的技术,可通过查找一个或多个域的所有 URL 从 Web 收集数据。Python 有几个流行的网络爬虫库和框架。
在本文中,我们将首先介绍不同的爬取策略和用例。然后我们将使用两个库在 Python 中从头开始构建一个简单的网络爬虫:requests 和 Beautiful Soup。接下来,我们将了解为什么最好使用像 Scrapy 这样的网络爬虫框架。最后,我们将使用 Scrapy 构建一个示例爬虫,以从 IMDb 收集电影元数据,并了解 Scrapy 如何扩展到拥有数百万页的网站。
什么是网络爬虫?
网络爬行和网络抓取是两个不同但相关的概念。网络爬虫是网络爬虫的一个组成部分,爬虫逻辑寻找爬虫代码要处理的URL。
网络爬虫以要访问的 URL 列表开始,称为种子。对于每个 URL,爬网程序在 HTML 中查找链接,根据某些条件过滤这些链接并将新链接添加到队列中。提取所有 HTML 或某些特定信息以供不同的管道处理。
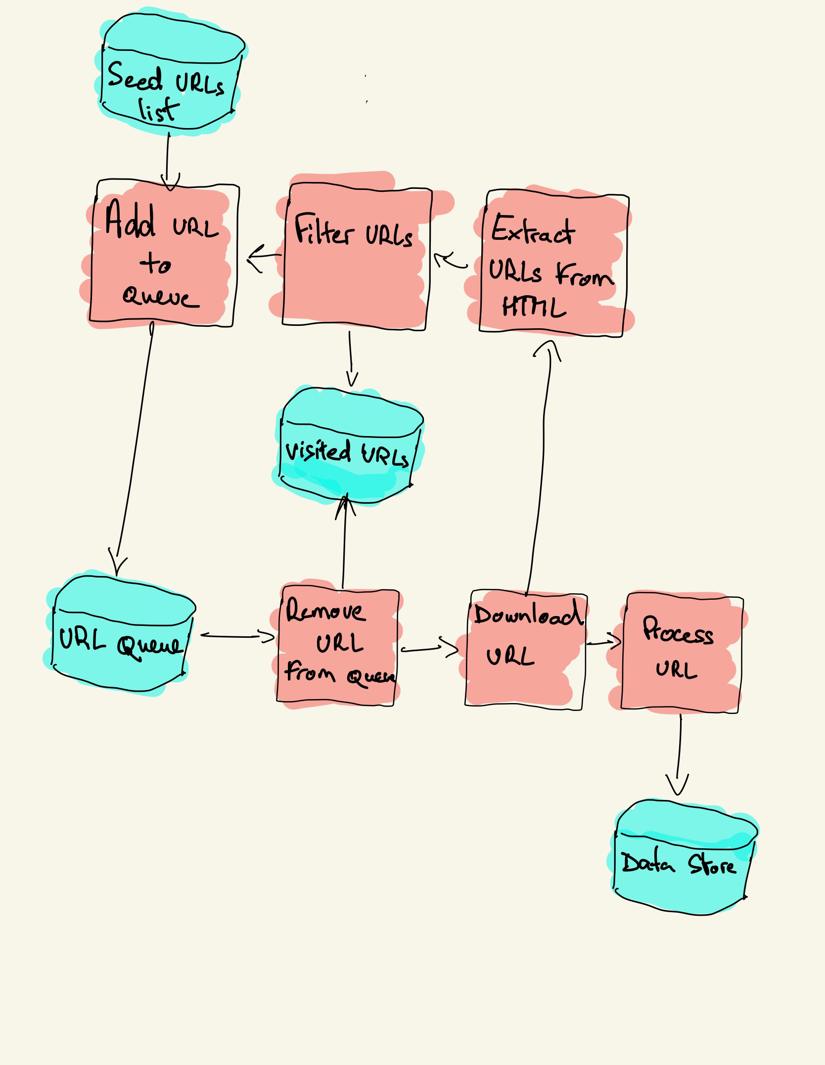
网页抓取策略
在实践中,网络爬虫只访问页面的一个子集,这取决于爬虫预算,这可以是每个域的最大页面数、深度或执行时间。
大多数流行的网站都提供了一个robots.txt文件来指示每个用户代理禁止抓取网站的哪些区域。与 robots 文件相对的是sitemap.xml文件,该文件列出了可以抓取的页面。
流行的网络爬虫用例包括:
-
搜索引擎(Googlebot、Bingbot、Yandex Bot……)收集 Web 重要部分的所有 HTML。此数据已编入索引以使其可搜索。
-
除了收集 HTML 之外,SEO 分析工具还收集元数据,例如响应时间、检测损坏页面的响应状态以及不同域之间的链接以收集反向链接。
-
价格监控工具抓取电子商务网站以查找产品页面并提取元数据,尤其是价格。然后定期重新访问产品页面。
-
Common Crawl 维护着一个开放的网络爬行数据存储库。例如,2020 年 10 月的档案包含 27.1 亿个网页。
接下来,我们将比较在 Python 中构建网络爬虫的三种不同策略。首先,仅使用标准库,然后是用于发出 HTTP 请求和解析 HTML 的第三方库,最后是网络爬虫框架。
从头开始用 Python 构建一个简单的网络爬虫
要在 Python 中构建一个简单的网络爬虫,我们至少需要一个库来从 URL 下载 HTML,以及一个 HTML 解析库来提取链接。Python 提供了用于发出 HTTP 请求的标准库 urllib 和用于解析 HTML 的 html.parser。可以在 Github上找到仅使用标准库构建的示例 Python 爬虫。
用于请求和 HTML 解析的标准 Python 库对开发人员不是很友好。其他流行的库如 requests,标记为人类的 HTTP 和 BeautifulSoup 提供更好的开发人员体验。
如果您想了解更多信息,可以查看有关最佳 Python HTTP 客户端的指南。
您可以在本地安装这两个库。
pip install requests bs4
可以按照前面的架构图构建一个基本的爬虫。
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
logging.basicConfig(format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)
class Crawler:
def __init__(self, urls=[]):
self.visited_urls = []
self.urls_to_visit = urls
def download_url(self, url):
return requests.get(url).text
def get_linked_urls(self, url, html):
soup = BeautifulSoup(html, 'html.parser')
for link in soup.find_all('a'):
path = link.get('href')
if path and path.startswith('/'):
path = urljoin(url, path)
yield path
def add_url_to_visit(self, url):
if url not in self.visited_urls and url not in self.urls_to_visit:
self.urls_to_visit.append(url)
def crawl(self, url):
html = self.download_url(url)
for url in self.get_linked_urls(url, html):
self.add_url_to_visit(url)
def run(self):
while self.urls_to_visit:
url = self.urls_to_visit.pop(0)
logging.info(f'Crawling: {url}')
try:
self.crawl(url)
except Exception:
logging.exception(f'Failed to crawl: {url}')
finally:
self.visited_urls.append(url)
if __name__ == '__main__':
Crawler(urls=['https://www.imdb.com/']).run()
上面的代码定义了一个 Crawler 类,其中包含使用 requests 库的 download_url、使用 BeautifulSoup 库的 get_linked_urls 和过滤 URL 的 add_url_to_visit 的辅助方法。要访问的 URL 和已访问的 URL 存储在两个单独的列表中。您可以在终端上运行爬虫。
python crawler.py
爬虫为每个访问过的 URL 记录一行。
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/
2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home
2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal
2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd
2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_250
2020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm
2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_gr
代码非常简单,但在成功抓取完整网站之前,还有许多性能和可用性问题需要解决。
-
爬虫很慢,不支持并行。从时间戳可以看出,抓取每个 URL 大约需要一秒钟。每次爬虫发出请求时,它都会等待请求得到解决,并且在这之间不做任何工作。
-
下载 URL 逻辑没有重试机制,URL 队列不是真正的队列,并且在 URL 数量较多时效率不高。
-
链接提取逻辑不支持通过删除 URL 查询字符串参数来标准化 URL,不处理以 # 开头的 URL,不支持按域过滤 URL 或过滤掉对静态文件的请求。
-
爬虫无法识别自身并忽略 robots.txt 文件。
接下来,我们将看到 Scrapy 如何提供所有这些功能,并使您可以轻松扩展自定义爬网。
使用 Scrapy 抓取网页
Scrapy 是最受欢迎的网络抓取和爬行 Python 框架,在Github上拥有 40k 星。Scrapy 的优点之一是请求是异步调度和处理的。这意味着 Scrapy 可以在前一个请求完成之前发送另一个请求,或者在两者之间做一些其他工作。Scrapy 可以处理许多并发请求,但也可以配置为尊重具有自定义设置的网站,我们稍后会看到。
Scrapy 具有多组件架构。通常,您将至少实现两个不同的类:Spider 和 Pipeline。Web 抓取可以被认为是一种 ETL,您可以在其中从 Web 中提取数据并将其加载到您自己的存储中。蜘蛛提取数据,然后管道将其加载到存储中。转换可以在蜘蛛和管道中发生,但我建议您设置一个自定义的 Scrapy 管道来相互独立地转换每个项目。这样,处理一个项目失败对其他项目没有影响。
最重要的是,您可以在组件之间添加蜘蛛和下载器中间件,如下图所示。

Scrapy 架构概述
如果您之前使用过 Scrapy,您就会知道 Web 爬虫被定义为一个类,该类继承自 Spider 基类并实现了一个 parse 方法来处理每个响应。如果您是 Scrapy 的新手,您可以阅读这篇文章,以便使用 Scrapy 轻松抓取。
from scrapy.spiders import Spider
class ImdbSpider(Spider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
def parse(self, response):
pass
Scrapy 还提供了几个通用的蜘蛛类:CrawlSpider、XMLFeedSpider、CSVFeedSpider 和 SitemapSpider。该 CrawlSpider 从基类蜘蛛类继承,并提供了一个额外的规则属性来定义如何抓取网站。每个规则使用一个 LinkExtractor 来指定从每个页面中提取哪些链接。接下来,我们将通过为互联网电影数据库 IMDb 构建一个爬虫来了解如何使用它们中的每一个。
为 IMDb 构建示例 Scrapy 爬虫
在尝试抓取 IMDb 之前,我检查了 IMDb robots.txt 文件以查看允许哪些 URL 路径。robots 文件只禁止所有用户代理使用 26 条路径。Scrapy 预先读取 robots.txt 文件并在 ROBOTSTXT_OBEY 设置为 true 时尊重它。使用 Scrapy 命令 startproject 生成的所有项目都是这种情况。
scrapy startproject scrapy_crawler
此命令使用默认的 Scrapy 项目文件夹结构创建一个新项目。
scrapy_crawler/
├── scrapy.cfg
└── scrapy_crawler
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
然后你可以在 scrapy_crawler/spiders/imdb.py 中创建一个蜘蛛,并使用规则来提取所有链接。
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (Rule(LinkExtractor()),)
您可以在终端中启动爬虫。
scrapy crawl imdb --logfile imdb.log
您将获得大量日志,包括每个请求的一个日志。浏览日志我注意到,即使我们将 allowed_domains 设置为只抓取下面的网页https://www.imdb.com,有对外部域的请求,例如 amazon.com。
2020-12-06 12:25:18 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET [https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba](https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>
IMDb 从 whitelist-offsite 和 whitelist 下的 URL 路径重定向到外部域。有一个开放的 Scrapy Github 问题表明,在 RedirectMiddleware 之前应用 OffsiteMiddleware 时,外部 URL 不会被过滤掉。为了解决这个问题,我们可以将链接提取器配置为拒绝以两个正则表达式开头的 URL。
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (
Rule(LinkExtractor(
deny=[
re.escape('https://www.imdb.com/offsite'),
re.escape('https://www.imdb.com/whitelist-offsite'),
],
)),
)
Rule 和 LinkExtractor 类支持多个参数来过滤 URL。例如,您可以忽略特定的 URL 扩展并通过对查询字符串进行排序来减少重复 URL 的数量。如果你没有找到你的使用情况特定的参数,你可以通过自定义函数来 process_links 在 LinkExtractor 或 process_values 的规则。
例如,IMDb 有两个具有相同内容的不同 URL。
https://www.imdb.com/name/nm1156914/
https://www.imdb.com/name/nm1156914/?mode=desktop&ref_=m_ft_dsk
为了限制抓取的 URL 的数量,我们可以使用 w3lib 库中的url_query_cleaner函数从URL 中删除所有查询字符串,并在 process_links 中使用它。
from w3lib.url import url_query_cleaner
def process_links(links):
for link in links:
link.url = url_query_cleaner(link.url)
yield link
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (
Rule(LinkExtractor(
deny=[
re.escape('https://www.imdb.com/offsite'),
re.escape('https://www.imdb.com/whitelist-offsite'),
],
), process_links=process_links),
)
现在我们已经限制了要处理的请求数量,我们可以添加一个 parse_item 方法来从每个页面中提取数据并将其传递给管道进行存储。例如,我们可以提取整个 response.text 以在不同的管道中对其进行处理,或者选择 HTML 元数据。要在 header 标签中选择 HTML 元数据,我们可以编写我们自己的 XPATH,但我发现使用库extruct 更好,它从 HTML 页面中提取所有元数据。您可以使用 pip install extract 安装它。
import re
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from w3lib.url import url_query_cleaner
import extruct
def process_links(links):
for link in links:
link.url = url_query_cleaner(link.url)
yield link
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (
Rule(
LinkExtractor(
deny=[
re.escape('https://www.imdb.com/offsite'),
re.escape('https://www.imdb.com/whitelist-offsite'),
],
),
process_links=process_links,
callback='parse_item',
follow=True
),
)
def parse_item(self, response):
return {
'url': response.url,
'metadata': extruct.extract(
response.text,
response.url,
syntaxes=['opengraph', 'json-ld']
),
}
我将 follow 属性设置为 True,这样即使我们提供了自定义解析方法,Scrapy 仍会跟踪来自每个响应的所有链接。我还配置了 extruct 以仅提取Open Graph 元数据和JSON-LD,这是一种在 Web 中使用 JSON 编码链接数据的流行方法,由 IMDb 使用。您可以运行爬网程序并将 JSON 行格式的项目存储到文件中。
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlines
输出文件 imdb.jl 为每个已爬取的项目包含一行。例如,从 HTML 中的 标记中提取的电影的开放图谱元数据如下所示。
{
"url": "http://www.imdb.com/title/tt2442560/",
"metadata": {"opengraph": [{
"namespace": {"og": "http://ogp.me/ns#"},
"properties": [
["og:url", "http://www.imdb.com/title/tt2442560/"],
["og:image", "https://m.media-amazon.com/images/M/MV5BMTkzNjEzMDEzMF5BMl5BanBnXkFtZTgwMDI0MjE4MjE@._V1_UY1200_CR90,0,630,1200_AL_.jpg"],
["og:type", "video.tv_show"],
["og:title", "Peaky Blinders (TV Series 2013\u2013 ) - IMDb"],
["og:site_name", "IMDb"],
["og:description", "Created by Steven Knight. With Cillian Murphy, Paul Anderson, Helen McCrory, Sophie Rundle. A gangster family epic set in 1900s England, centering on a gang who sew razor
blades in the peaks of their caps, and their fierce boss Tommy Shelby."]
]
}]}
}
单个项目的 JSON-LD 太长,无法包含在文章中,这里是 Scrapy 从 标签中提取的示例。
"json-ld": [
{
"@context": "http://schema.org",
"@type": "TVSeries",
"url": "/title/tt2442560/",
"name": "Peaky Blinders",
"image": "https://m.media-amazon.com/images/M/MV5BMTkzNjEzMDEzMF5BMl5BanBnXkFtZTgwMDI0MjE4MjE@._V1_.jpg",
"genre": ["Crime","Drama"],
"contentRating": "TV-MA",
"actor": [
{
"@type": "Person",
"url": "/name/nm0614165/",
"name": "Cillian Murphy"
},
...
]
...
}
]
在浏览日志时,我注意到爬虫的另一个常见问题。通过依次点击过滤器,爬虫会生成具有相同内容的 URL,只是过滤器的应用顺序不同。
https://www.imdb.com/name/nm2900465/videogallery/content_type-trailer/related_titles-tt0479468 https://www.imdb.com/name/nm2900465/videogallery/related_titles-tt0479468/content_type-trailer
长过滤器和搜索 URL 是一个难题,可以通过使用 Scrapy 设置URLLENGTH_LIMIT限制 URL 长度来部分解决。
我以 IMDb 为例,展示了在 Python 中构建网络爬虫的基础知识。我没有让爬虫运行太久,因为我没有数据的特定用例。如果您需要来自 IMDb 的特定数据,您可以查看IMDb 数据集项目,该项目提供 IMDb 数据和IMDbPY的每日导出,这是一个用于检索和管理数据的 Python 包。
大规模网络爬行
如果您尝试抓取像 IMDb 这样的大型网站,它有超过 4500 万个基于 Google 的页面,那么通过配置以下设置来负责任地抓取非常重要。您可以在 BOT_NAME 设置中识别您的抓取工具并提供详细联系信息。要限制您对网站服务器施加的压力,您可以增加 DOWNLOAD_DELAY、限制 CONCURRENT_REQUESTS_PER_DOMAIN 或设置 AUTOTHROTTLE_ENABLED 以根据服务器的响应时间动态调整这些设置。
请注意,默认情况下,Scrapy 爬网针对单个域进行了优化。如果您正在抓取多个域,请检查这些设置以优化广泛抓取,包括将默认抓取顺序从深度优先更改为呼吸优先。要限制您的抓取预算,您可以使用关闭蜘蛛扩展的 CLOSESPIDER_PAGECOUNT 设置来限制请求数量。
使用默认设置,Scrapy 每分钟为 IMDb 等网站抓取大约 600 个页面。要爬取 4500 万个页面,单个机器人需要 50 多天。如果您需要抓取多个网站,最好为每个大网站或网站组启动单独的抓取工具。如果您对分布式 Web 抓取感兴趣,您可以阅读开发人员如何使用 20 个 Amazon EC2 机器实例在 40 小时内使用 Python抓取 2.5 亿个页面。
在某些情况下,您可能会遇到需要您执行 JavaScript 代码来呈现所有 HTML 的网站。否则,您可能无法收集网站上的所有链接。因为现在网站在浏览器中动态呈现内容非常普遍,所以我编写了一个Scrapy 中间件来使用 ScrapingBee 的 API呈现 JavaScript 页面。
结论 我们将使用第三方库下载 URL 和解析 HTML 的 Python 爬虫的代码与使用流行的网络爬虫框架构建的爬虫进行了比较。Scrapy 是一个非常高性能的网络爬虫框架,很容易用你的自定义代码进行扩展。但是您需要知道所有可以挂钩您自己的代码的位置以及每个组件的设置。
在抓取具有数百万个页面的网站时,正确配置 Scrapy 变得更加重要。如果您想了解有关网络爬行的更多信息,我建议您选择一个受欢迎的网站并尝试对其进行爬行。你肯定会遇到新的问题,这让这个话题引人入胜!
文章来源:Ari Bajo





