如何判断一个 IP 是爬虫

通过 IP 判断爬虫
如果你查看服务器日志,看到密密麻麻的 IP 地址,你一眼可以看出来那些 IP 是爬虫,那些 IP 是正常的爬虫,就像这样:
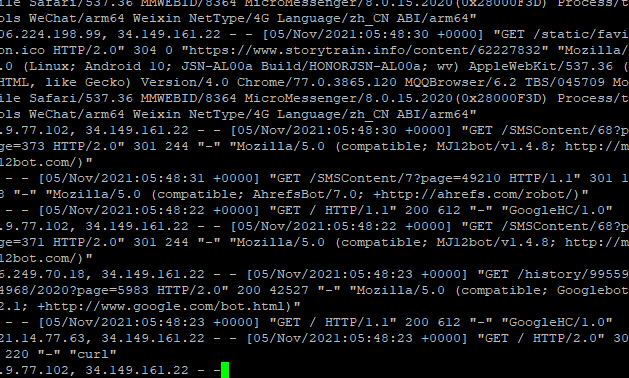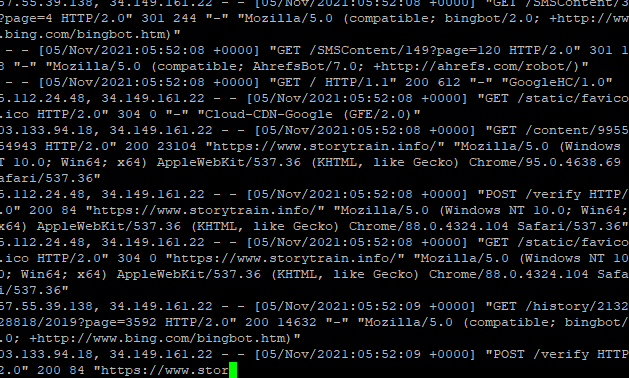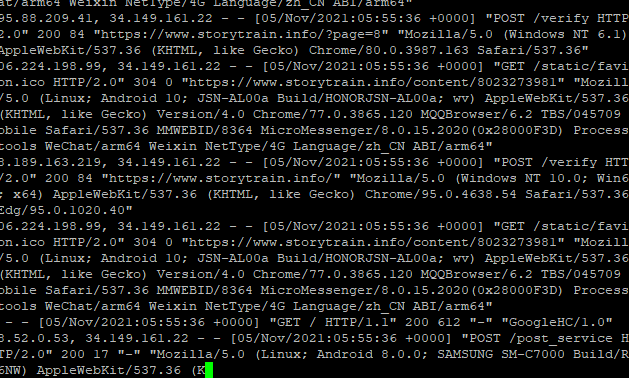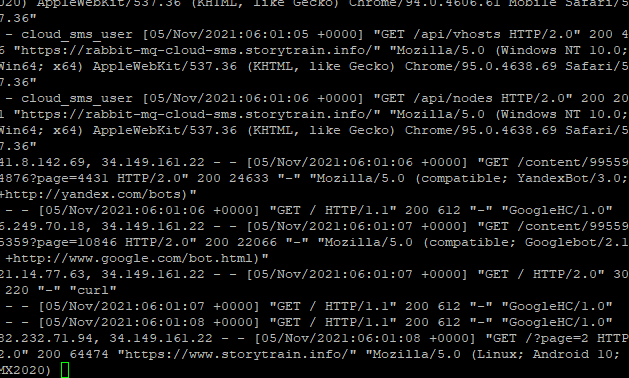
在这密密麻麻的日志里面,我们不仅要分辨出真正的爬虫 IP ,同时也要分辨出伪造的爬虫 IP,实属不易。
如果查看服务器日志,我们可以先通过 User-agent 大致判断出是爬虫还是正常用户,例如:
Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html) 这个是 SemrushBot 的爬虫
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) 这个是 bing 搜索引擎的爬虫
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.97 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) 这个是 Google 搜索引擎的爬虫
......
这些都是爬虫的 User-agent,只要是开发过爬虫的小伙伴都知道,User-agent 可以伪造的,仅仅通过 User-agent 来判断爬虫是不准确的,我们还要通过 IP 地址判断是否是爬虫。
66.249.71.19 - - [19/May/2021:06:25:52 +0800] "GET /history/16521060410/2019 HTTP/1.1" 302 257 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.97 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
上面这条日志,第一个是爬虫的 IP ,你确定它是 Google 搜索引擎的爬虫(蜘蛛)IP 吗?
我们可以通过 IP 反查,可以看出来 Hostname 是:crawl-66-249-71-19.googlebot.com
通过 ping 获取此 Hostname 的 IP 地址是:66.249.71.19
这个是 Google 搜索引擎的爬虫(蜘蛛)IP 确定无疑。
但是对于有些不确定的,我们也可以通过[IP 查询 - 爬虫识别]这个网站查询爬虫的具体信息。
具体操作不在此赘述,直接输入 IP 即可查询爬虫的详细信息,同时也可以参考这篇文章:爬虫进行 IP 识别,有具体用法。
通过以上的一些步骤,应该能很轻松的通过 IP 来判断是不是爬虫了。